OpenMP
OpenMP (Open Multi-Processing) es una un conjunto de comandos y rutinas, portables y escalables, que permite la paralelización de tareas dentro de un programa. Trabaja con paralelización multi-threaded y shared memory (de memoria compartida). Sus objetivo es ser estandarizado , portable , discreto, eficiente y fácil de usar. Tiene soporte para Fortran y C/C++.
El hecho de que openMP use un modelo de memoria compartida trae un problema inherente conocido como race-conditions. Esto es cuando distintos procesos acceden a una misma porción de memoria y la leen o escriben haciendo que el resultado del cálculo cambie arbtitrariamente dependiendo de cual proceso accedio primero. La forma de evitar estos conflictos es atraves de la sincronización de threads. La sincronización puede afectar significativamente la performance del programa por lo que hay que intentar minimizarla.
Modelo de programación Fork-Join
OpenMP sigue un modelo conocido como fork-join donde se distinguen regiones seriales (con un único thread) y regiones paralelas (multiple threads)
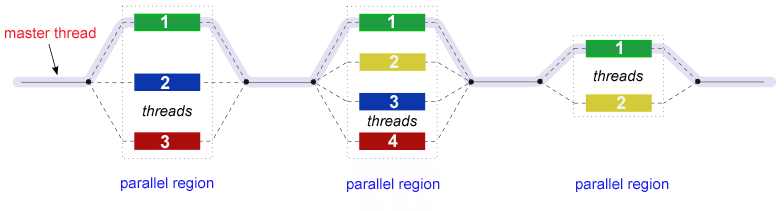
Regiones paralelas:
Para indicar que comienza una porción del código a ser corrido en paralelo se indica:
!$omp parallel
!(Acá va la region paralela)
!$omp end parallel
Lo que queda encerrado entre ese bloque se paraleliza. En esta región del código se asigna un thread master y varios slave threads.
Ejemplo simple: Hola mundo
OpenMP ya está incluido en la mayoría de los compiladores comunmente utilizados, por lo que no requiere ninguna compilación ni instalación.
Un programa “Hola mundo” en fortran sería:
program hola
use omp_lib
!$omp parallel
print '("Hello world! ",I0,"/",I0)',omp_get_thread_num(),omp_get_num_threads()
!$omp end parallel
end program
En C sería:
#include <stdio.h>
int main(){
#pragma omp parallel
{
//printf("Hola mundo!\n");
printf("Hola mundo! %d/%d\n",omp_get_thread_num(),omp_get_num_threads());
}
}
Al compilar, para que el script soporte openMP hay que agregar un comando para habilitarlo, para GNU es:
$> gfortran -fopenmp hola_omp.f90
Para correr un programa compilado con openMP primero hay que indicar el numero de threads y luego ejecutarlo
export OMP_NUM_THREADS=4
./a.out
Sincronización
La sincronización se usa para imponer orden entre procesos y proteger el acceso a la memoria compartida.
OpenMP tiene los siguientes comandos de alto nivel para la sincronización:
critical: (exclusión mutua) los threads esperan su turno para ejecutar el codigo (uno a la vez).atomic:barrierorderer
También hay otros comandos de bajo nivel:
flushlocks
Interacción entre threads
- Entre threads se comunican utilizando variables compartidas (shared variables).
- Los threads comunmente necesitan algun espacio de trabajo privado junto con variables compartidas (por ejemplo el indice de un loop).
- La visibilidad de diferentes variables es definida usando clausulas de datos compartidos (data sharing clauses) en la region paralela.
Almacenamiento default
- Por default las variables son compartidas.
- Las variables globales son compartidas.
- Variables privadas: aquellas definidas dentro de la region paralela, y variables automaticas dentro de un bloque.
Atributos de compartición de datos:
private(*lista*)Pertenece a cada thread, y poseé valor inicial indefinido y valor final indefinido.firstprivate()Igual aprivatesólo que comienza con un valor incial, definido afuera de la region paralela.lastprivate()Igual queprivatepero sale con un valor definido en la última iteración de la region paralela.shared()Variables compartidas, todos los threads pueden leer y editarlas. (Por default todas las variables son compartidas).thradprivate()Variable global privada. Usada para hacer privada a cada thread variables globales.copyin()Cioauar valores del master thread a los otros threads.
Se puede definir por default que usar: default(private/shared/none)
Comandos de trabajo compartido
Las regiones paralelas crean un programa simple de datos multiples donde cada thread ejecuta el mismo codigo.
Para dividir el trabajo entre threads en una region paralela pueden utilizarse:
- Loops
- Secciones
- Taks
- Workshare
Loop
Para hacer que se comparta el trabajo de un loop.
!$OMP DO(debe estar adentro de una región paralela)!$OMP DO PARALLEL(combinar loop con parallel)- Los indices de cada loop son privados por default.
El trabajo compartido puede ser controlado utilizando las clausulas de schedule() (esquema)
schedule(*static[,n]*)bloques de iteraciones de tamaño n para cada thread.schedule(*dynamic[,n]*)n iteraciones de una cola hasta que todo esté realizado.schedule(*guided[,n]*)threads agarran bloques de iteraciones. El tamño de los bloques empiezan de mayor tamaño hasta n.schedule(*runtime*)El esquema y n son tomados de la variable OMP_SCHEDULE
Reducción
Race conditions: Ocurren cuando multiples threads leen y escriben una misma variable simultaneamente. Esto produce resultados aleatorios dependiendo del orden de acceso de los threads.
Ejemplo:
asum=0.0
!$OMP PARALLEL DO SHARED(x,y,n,asum) PRIVATE(i)
do i=1, n
asum= asum + x(i)*y(i)
end do
!$OMP END PARALLEL DO
Por lo tanto se necesita algún mecanísmo para controlar el acceso.
reduction(operador:lista)
- Realiza reducción en la variable de la lista.
- Una variable de reducción privada se crea en cada resultado parcial del thread.
- Una variable privada de reducción es inicializada al valor inicial del operador.
- Despues de la region paralela la reducción se aplica a las variables privadas y el resultado se agrega a la variable compartida.
- Operadores (
+,-,*,.AND.,.OR.,.NEGV.,.IEOR.,.IOR.,.IAND.,.EQV.,MIN,MAX)
Ejemplo:
fortran
!$OMP PARALLEL DO SHARED(x,y,n,asum) PRIVATE(i) REDUCTION(+:asum)
do i=1, n
asum= asum + x(i)*y(i)
end do
!$OMP END PARALLEL DO
(!) Dado que la suma y el producto con punto flotante no es asociativa, es posible que se obtenga distintos valores cada vez que se ejecuta el programa.
Buenas prácticas:
- Maximizar/Optimizar regiones paralelas, es decir, reducir numero de llamadas a regiones paralelas (fork-join overhead)
- Paralelizar todos los loops que sean posibles.
- Reducir acceso a datos compartidos.
- Para controlar race conditions usar sincronización para evitar confictos de datos
- Cambiar como acceder a los datos para evitar necesidad de sincronización.
Secciones
Ejecución paralela de regiones de codigo independientes, cada una con un thread: !$OMP SECTIONS !$OMP SECTION
Comunmente usado para asignar diferentes llamadas a subrutinas a diferentes threads.
Dificil de cargar balancce
!$OMP PARALLEL
!$OMP SECTIONS
!$omp section
call do_a()
!$omp section
call do_b()
!$omp section
call do_c()
!$OMP END SECTIONS
!$OMP END PARALLEL
Tasks
Asignar tasks (tareas) a cada thread !$OMP TASK
Cada task tiene:
- Código que ejecutar.
- Datos de entorno.
- Un thread que lo ejecute.
La cola de taks es manejada por ompenMP runtime
integer :: a
subroutine foo()
integer :: b, a
!$OMP PARALLEL firstprivate(b)
!$OMP TASK SHARED(c)
call bar(b,c)
!$OMP END TASK
!$OMP END PARALLEL
end subroutine foo
subroutine bar(b,c)
integer :: b,c,d
! scope of a: shared
! scope of b: firstprivate
! scope of c: shared
! scope of d: private
subroutine bar
integer x
!$OMP PARALLEL
!$OMP SINGLE
x= fib(n)
!$OMP END SINGLE
!$OMP END PARALLEL
contains
recursive function fib(n) result(fn)
integer :: j,n,fnm, fn
if (n<2) then
fn=n
return
else if (n<10)
fn fibo_secuencial(n) !Una funcion secuencial de fibonacci
return
end if
!$OMP TASK SHARED(fn)
fn= fib(n-1)
!$OMP END TASK
!$OMP TASK shared(fnm)
fnm= fib(n-2)
!$OMP END TASK
!$OMP TASKWAIT
fn= fn+fnm
end function
Workshare construct
!$OMP WORKSHARE
Restricción: el bloque de código solo puede contenter:
- asignaciones con arrays y escalares.
- comandos
forall()ywhere() - comandos openMP:
atomic,criticalyparallel - (No puede llamar a funciones (salvo ELEMEMENTAL)
real A(100,100), B(100,100)
call random_number(A)
!$OMP PARALLEL_SHARED(A,B)
!$OMP WORKSHARE
where (A<0.5)
B=0.0
elsewhere
B=1.0
end where
!$OMP END WORKSHARE
!$OMP END PARALLEL
Sincronización
Aveces parte de la region paralela debe ser ejecutada sólo por el master thread ó por un solo thread a la vez. (I/O inicialización, actualización de valores globales, etc.)
OpenMP provée de clausulas para controlar la ejecución de bloques de código.
barrierEspera a que todos los threads terminen para continuar.critical(mutual exclusión). Crea una sección crítica: zona que debe ser ejecutada por cada thread a la vez.atomicActualiza un valor determinado.ordererSincroniza todos los threads en ese punto.singleZona que debe ser ejecutada por sólo un thread (arbitrario)masterZona que sdebe ser ejecutada sólo por el master (threadId==0)flushSincroniza la memoria de todos los threats.nowait
Variables de entorno
OpenMP provée de varias formas para interactuar con el entorno de ejecución, estas operaciones incluyen:
- seteo de numero de threads por region paralela.
- pedido de numero de cpus.
- cambiar el schedule default de trabajo. Hay una serie de variables de entorno que hay que setear:
OMP_SCHEDULEOMP_NUM_THREADSOMP_DYNAMICOMP_PROC_BINDOMP_NESTEDOMP_STACKSIZEOMP_WAIT_POLICYOMP_MAX_ACTIVE_LEVELSOMP_THREAD_LIMIT
Operanciones en run-time:
- Modificar ó ver numero de threads:
omp_set_num_threads()omp_get_num_threads()omp_get_thread_num()omp_get_max_threads()
- Consultar si se está en una region paralela:
omp_in_parallel() - Cambiar numero de threads dinamicamente:
omp_set_dynamic(),omp_get_dynamic() - Cuantos procesadores hay en el sistema:
omp_get_num_procs()
Control de ejecución: LOCKS y paralelismo anidado
Hay dos tipos de locks: simple y anidado
integer (kind=omp_lock_kind) svar
integer (kind=omp_nest_lock_kind) svar
Los locks habilitan:
- implementación de comportamiento asincrónico.
- control de ejecución no-estructurada. Debe ser manipulada sólo desde OpenMP. Si no se inicializa el comportamiento es indefinido.
Los locks proveen funcionalidades análogas a semáforos
Sintaxis: su subroutine OMP_(init/set/destroy)_LOCK(svar) subroutine OMP_(init/set/destroy)_nest_LOCK(svar)
Workflow:
- Definir una variable lock
- Inicializar con
omp_init_lock - setear con
omp_set_lockóomp_test_lock - Liberar con
omp_unset_lock - Destruir con
omp_destroy_lock
Ejemplo:
integer (kind=omp_lock_kind) lock
call omp_init_lock(lock)
!$OMP PARALLEL
do while (.not. omp_test_lock(lock))
!Hacer algo
end do
!call omp_unset_lock(lock)
!$OMP END PARALLEL
call omp_destroy_lock(lock)
Hardware
Jerarquía de memoria, afinidad
Las computadoras de memoria compartida (shared memory) pueden ser de dos tipos:
- Simetric Multi-Procesor (SMP): Tiene más de una CPU por nodo.
- La memoria es accesible para todos los procesadores y con el mismo tiempo de acceso (latencia).
- Menor costo debido a que comparten conectores y peripherals
- Mayor rápidez en la comunicación entre sockets.
- Mayor memoria compartida para programas híbridos.
- Non-Uniform Memory Access (NUMA)
- Toda la memoria es accesible pero la latencia y el ancho de banda puede variar.
- Diferentes regiones de la memoria tienen distinto tiempo de acceso (memoria “cercana” y “lejana”).
Afinidad
Los S.O asignan threads y procesos a determinados nucleos. Por ejemplo, en linux por default se utiliza soft affinity (el SO intenta evitar mover threads de un nucleo a otro.)
Para la mayor eficiencia computacional es util asociar (pin) threads a nucleos especificos.
Para configurar afinidad en GNU se utiliza: GOMP_CPU_AFFINITY ="0-6"
Coherencia del cache (false sharing)
Los caches de las nuevas CPUs son complejos. Los datos son leidos/escritos como lineas de cache enteras (generalmente 64bits) Los modelos de programación requiren que la información en la memoria sea consistente (un address solo puede tener un valor).
Cuando diferentes threads modifican ubicación en memoria sucesivamente, la coeherencia del cache forza estas actualizaciones a ser transferidas entre todas las copias de cache. Si esto ocurre en una rapida sucesión hay una penalidad muy grande en la performance debido a perdidas de caches. Para evitarlo, reorganizar el acceso a los datos de forma tal que cada thread modifique valores dentro de un bloque más grande, ó usar variables privadas. (Esto no ocurre cuando los datos son solo leídos).
Licensed MIT.