HPC
La computación de alto rendimiento implica usar la potencia de cálculo para resolver problemas complejos en ciencia, intengiería y gestión. Para lograr este objetivo, la computación de alto rendimiento se apoya en tecnologías computacionales como los clusters, los supercomputadores o la computación paralela.
Primero veamos las diferencias entre la computación serial y paralela:
- Computación serial: Tradicionalmente el software se escribía para computación en serie. Esto quiere decir que un problema se descomponía en una secuencia de instrucciones, y cada una de estas era ejecutada secuencialmente (una después de la otra) en un sólo procesador, y por lo tanto en cada instante de tiempo una sola instrucción era ejecutada.
- Computación paralela: Es el uso simultanteo de recursos computacionales para resolver un problema. El problema se descompone en partes discretas que pueden ser resueltas concurrentemente. Cada parte es descompuesta en una serie de instrucciones, y cada una de ellas puede ser ejecutada en diferentes procesadores al mismo tiempo. Para ello se require un controlador global que coordine y una todos los procesos que se llevan a cabo de forma separada. Para resolver un problema en forma paralela, este debe ser capaz de ser descompuesto en partes que se resuelvan simultaneamente. Los recursos computacionales usados pueden ser computadoras con multiples procesadores (cores/núcleos) ó varias computadoras en red.
Ejemplo de problema paralelo: los partidos de la copa del mundo.

En cada etapa (octavos, cuartos, semi y final) los partidos pueden ser ejecutados en forma paralela, mientras que la ejecución de etapas debe ser en forma serial. Es decir este problema es serial en el sentido horizontal, y paralelo en el sentido vertical.
Por qué es importante aprender HPC?
Ley de Moore: El número de transistores en un circuito integrado se duplica cada 2 años.
Entre 1968 a 2003 la performance de los microprocesadores aumentaron en promedio más del 50% por año. Gran parte de este incremento se debe al aumento de la densidad de transistores en los sistemas integrados. A medida que disminuye el tamaño de los transistores también aumenta su velocidad pero junto a esto el consumo de energía aumenta también. Mucho de la energía consumida se disipa como calor y cuando un circuito se calienta mucho puede empezar a tener fallos. Los circuitos refrigerados por aire ya ha llegado a su limite físico de discipación de calor. Es por esto que el número de ciclos que una CPU puede ejecutar por segundo (clock-speed) no aumenta desde el año 2000 (Intel Pentum 4).
Por lo tanto, desde el 2005 los productores de microprocesadores han decidido mejorar la performance a base de sistemas multi-core. En vez de desarrollar procesadores monolíticos más rápdidos han empezado a poner múltiple procesadores completos en los sistemas integrados.
Límites y costos de la computación paralela
Ley de Amdahl
Establece que la velocidad de un programa paralelo viene dada por:
donde p: fracción de código paralelizable.
Considerando el número de procesadores:
donde n: nuemero de procesadores, s:fración serial.
Esto muestra que por más que nos forcemos en paralelizar al máximo un programa, este siempre tendrá un asíntota con respecto al numero de procesadores que usemos. Por ejemplo para un código que se puede paralelizar al 95\% nunca vamos a alcanzar una velocidad mayor a 20 veces la velocidad en serial.
Paralelismo automatico
Muchos compiladores cuando analizan el código identifican oportunidades para paralelizar, particularmente en loops. En tal caso uno podría analizar el código e identificar inhibidores e intentar eliminarlos de forma tal que el compilador pueda identificarlo y paralelizar.
De todas formas aún no existen implementaciones de compiladores que paralelizen automáticamente de forma eficiente y lo más común es que la paralelización se realice manualmente en base a directivas realizadas por el programador.
Diseño de programas paralelos
Sin duda, el primer paso a desarrollar un programa paralelo es entender en primer lugar el problema que se quiere resolver en paralelo. Y analizar antes si el problema es realmente paralelizable.
En caso que que sea paralelizable, es importante identificar:
- hotspots (regiones que demanden más poder de computo)
- cuellos de botella del programa
- inhibidores al paralelismo (el más común es la dependencia de datos).
En caso de que no sea un algoritmo paralelizable se puede buscar otros algoritmos posibles (si existen).
Ejemplo: Un ejemplo interesante para ilustrar esto es la serie de Fibonacci, esta seríe se construye algorítmicamente según:
donde los primeros dos elementos (f0 f1) son igual a 1. Este problema no es paralelizable por la dependencia del calculo de los elementos previos para la construcción de un nuevo elemento. Sin embargo existe un resultado matemático que podemos utilizar conocido como Fórmula de Binet:
donde φ= (1 + √5) / 2 = 1.6180339887…
este resultado es altamente paralelizable ya que no hay dependencia alguna entre elementos de la serie. Cada procesador puede computar uno distinto, solo sería necesario sincronizar y ordenar los numeros computados al final.
Partición
El primer paso en todo programa paralelo es descomponer el problema en pedazos discretos de trabajo (particionar).
Hay dos formas básicas de particionar un problema:
- Descomposición del dominio (paralelismo de datos): Esta asociado a descomponer los datos asociados al problema, y hacer que cada task trabaje en una porción de los datos. Por ejemplo se puede descomponer los datos en bloques ó ciclicamente.
- Descomposición funcional (paralelismo de tareas): Este se focaliza en el rol que cumple cada pedazo de código en la resolución de problema global. Por ejemplo en el modelado de la atmósfera se descomponen las rutinas en: dinámica, física (turbulencia, convección, radiación, nubes, etc.), química, océano, etc.
Ejemplo: Imaginemos que tenemos 5 profesores para corregir los examenes de una clase de 100 estudiantes. La corrección se puede organizar de dos formas: Cada profesor corrige un ejercicio de los 100 examenes (paralelización de tareas); la otra alternativa es que todos los profesores corrijan la totalidad del examen pero cada uno corrige 20 examenes (paralelización de datos). Acá las unidades de procesamientos serían los 5 profesores, los “datos” serían los estudiantes y las tareas (ó tasks) serian los ejercicios a corregir.
Hay varios elementos involucrados en la coordinación de un problema paralelo:
- Comunicación
- Balance de carga
- Sincronización
Comunicación
La comunicación sólo es necesaria cuando los tasks comparten datos. Si el problema a tratar se puede descomponer en muchos pedazos autónomos, entonces no es necesario hacer eso de ella. Algunos factores a considerar:
- Evitar sobre-comunicación (overhead)
- Latencia vs Ancho de banda
- Latencia: tiempo que demora enviar un mensaje de 0 bytes entre dos tasks (seg).
- Ancho de banda: cantidad de información que puede enviarse por unidad de tiempo (bytes/seg).
- Visibilidad de comunicaciones. Es deseable tener información sobre la comunicación entre tasks.
- Comunicación sincrónica vs asincrónica
- Estrategia de comunicación:
- Punto a punto
- Colectiva
- Eficiencia de comunicación
- Sobrecarga y complejidad
Sincronización
Tipos de sincronización:
- Barrier /Barrera: Todos los tasks están involucrados. Cuando el último task llega a la barrera entonces se sincronizan los taks.
- Lock/Semáforo: Puede involucrar cualquier numero de taks. Se usan para serializar/proteger acceso a datos globales. Sólo un task a la vez puede usar el lock.
- Sincrónica
Balance de carga
El balance de carga (load balancing) se refiera a la forma en que se distribuye la cantidad de trabajo entre tasks de forma tal de reducir la capacidad osciosa. Las estrategias posibles son:
- Distribución equitativa
- Asignación dinámica
Granularidad
Como ya se dijo, la granularidad hace referencia a la relación entre computación y comunicación.
- Granularidad fina
- Periodos cortos de computación intercaldos con eventos de comunicación.
- Facilita balance de carga.
- Granularidad gruesa
- Periodos largos de computos seguidos por sincornización.
- Mayor oportunnidad de incrementar performance.
- Dificil de balancear la carga.
Inhibidores de paralelismo
Dependencia
Decimos que hay dependencia entre instrucciones cuando el orden de ejecución de estos afecta el resultado del programa. También existe la dependencia de datos, esta resulta del uso múltiple de la misma locación de datos por distintos tasks. La dependencia es importante ya que es el principal inhibidor de paralelismo.
Input/Output
Las operaciones I/O son generalmente inhibidores de paralelismo. sin embargo existen sistemas de archivos adaptados a paralelización, por ejemplo: GPFS, Lustre, HDF
Nociones del hardware
Arquitectura de Von Neuman
Para entender la computación paralela es necesario tener algunos conocimientos básicos de cuales son los componentes de una computadora y como funciona. La mayoría de las computadoras electrónicas siguen la arquitectura de John Von Neuman también conocida como computadora de almacenamiento de programas, en ella tanto los programas, las instrucciones y los datos se guardan en una memoria electronica.
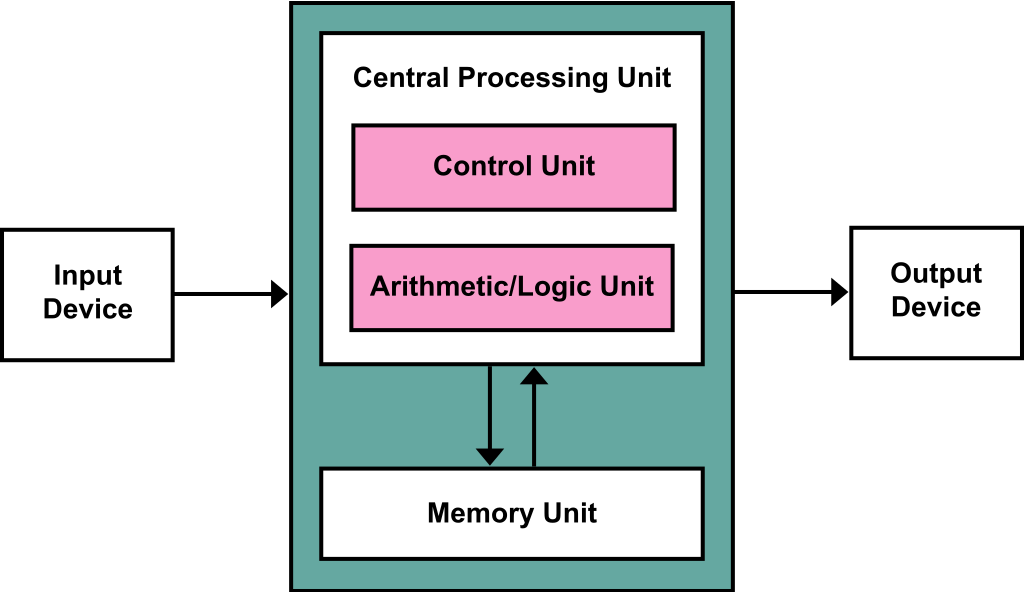
Los componentes de estas computadoras son:
- Memoria
- Cada espacio en la memoria tiene una dirección identificador llamado memory address.
- RAM (Random Access Memory) Es una memoria en la que el accesso a cualquier porción de información en ella demora el mismo tiempo (es una idealización).
- cache es la parte de la memoria de accesso más inmediato para un procesador.
- Unidad de Control (CU): se encarga de buscar instrucciones y datos de la memoria, decodificarlos y coordinar operaciones (secuencialmente) para resolver alguna tarea.
- Unidad Lógica/Aritmética (ALU). ejecuta operaciones lógicas y aritméticas.
- Dispositivo de Input/Output: hace referencia a la interfaz entre el humano (operador) y la computadora.
Comunmente denominámos Unidad de Procesamiento Central (CPU) al conjunto de la CU, ALU y una pequeña porción de memoria muy rápida llamada registro. La CU tiene un registro especial llamado contador que guarda la dirección de la próxima instrucción a ejecutar.
Las instrucciones y los datos son transferidos entre CPU y Memoria a travez de una red interconectada. Esto tradicionalmente se hacia a travez de un bus que consiste en una colección de cables y un hardware que controlaba el acceso a estos. Hoy en día se usa otro sistema.
La separación entre CPU y Memoria genera un importante cuello de botella ya que la velocidad a la que la CPU ejecuta instrucciones es mucho mayor a la velocidad en la que puede tomar datos de la memoria para ejecutarlos.
Procesos, multitasking y threads
El sistema operativo (SO) es el software que maneja el hardware y los recursos en la computadora. Determina que programas ejecutar, cuando y que memoria asignarle. Cuando uno ejecuta un programa el SO crea un proceso, que consise en:
- El ejecutable
- Una porción de memoria que contiene: el codigo ejecutable, un call stack que lleva la cuenta de las funciones acivas, una pila (heap).
- Descriptores de los recursos que el SO ha proporcionado.
- Información de seguridad
- Información sobre el estado del proceso.
Los SO modernos son multitasking es decis que sportan la ejecución conjunta de varios programas en “simultaneo”. En estos SO si un proceso necesita esperar algún recurso (por ejemplo leer un dato en una memoria externa, este se bloquea, es decir deja de ejecutarse así el SO puede seguir con otros procesos. Sin embargo parte del programa podría continuar ejecutandose aunque parte del programa esté esperando el recurso. La creación de threads proveen de un mecanismo para los progrmadores de dividir sus programas en task independientes con la propiedad que cuando un thread está bloqueado otro puede seguir ejecutandose. Es más rápido switchar entre threads que entre procesos ya que son más “livianos”. Los threads están contenidos dentro de un proceso, de forma que comparten ejecutable, memoria y otros recursos.
Modificaciones al modelo de Von Neumann
Caching
El cache es una colección de ubicaciones de memoria de más rapido acceso que otras ubicaciones de memoria. En particular el cache de la CPU pude estar ubicada en el mismo chip que la CPU o en un chip separado pero de acceso más rapido. En general lo que se guarda en el cache sigue la idea de que los programas tienden a usar datos e instrucciones que están físicamente cerca entre ellos (por ejemplo recorrer un array), esta idea se conoce como cercanía ó locality.
Para explotar este principio de locality los sistemas usan un sistema interconectado más ancho para acceder a datos e instrucciones. Es decir el acceso a memoria se hace en bloques. Estos bloques se conocen como cache blocks ó cache lines, estos almacenan entre 8/16 veces más información que una ubicación individual de memoria. Si bien solemos pensar al cache como un bloque homogeneo, suele tener niveles con distinta velocidad de acceso.
Mapeo del cache
Otro aspecto en el diseño del cache es donde se guardan las cache lines tomadas desde la memoria. Hay distintas formas de asignar a cada ubicación en memoria su correspondiente cache line:
- Fully associative. Una nueva linea puede guardarse en cualquier parte del cache.
- Mapeo directo. Cada linea tiene un lugar único en el cache.
- Set-associative. Cada linea tiene n-lugares posibles dentro del cache.
Memoria virtual
Los caches hacen posible que la CPU acceda rapidamente a instrucciones y datos que estan en la memoria principal. Pero cuando ejecutamos programas muy grandes es posible que los datos no entren en la memoria principal. La memoria virtual fue desarrollada para que la memoria principal pueda funcionar como un cache de almacenamiento secundario. Explota el principio de localidad espacial/temporal guardando solo las partes activas del ó los programas siendo ejecutados en un bloque conocido como swap space. Al igual que la CPU la memoria virtual opera sobre instrucciones y bloques de datos, estos son comunmente llamados pages, y dado a que el accesso es cientas de veces más lento suelen tener un tamaño grande (~4-16 kb)
Las memorias virtuales resuelven tres problemas:
- Falta de memoria RAM
- Fragmentación de memoria. Cuando no hay espacio contiguo para guardar datos usados por un programa (aunque si en total haya suficiente espacio en la RAM).
- Problemas de seguridad (address corruption)
Paralelismo de bajo nivel
Instruction-level parallelism, o ILP, intenta mejorar la performance del procesador teniendo multiples componentes del procesador o unidades funcionales ejecutando instrucciones simultaneamente. Hay dos formas de lo lograr ILP:
- pelining donde las unidades funcionales son organizadas en stages, y
- multiple issue, donde multiples instrucciones puedn ser inicializads simultaneamente
Hardware multi-threading
ILP can be very difficult to exploit: a program with a long sequence of dependent statements offers few opportunities. For example, in a direct calculation of the Fi- bonacci numbers
f[0]=f[1]=1
for (i=2;i<=n;i++)
f[i] = f[i-1] + f[i-2]
there’s essentially no opportunity for simultaneous execution of instructions. Thread-level parallelism, or TLP, attempts to provide parallelism through the simultaneous execution of different threads, so it provides a coarser-grained paral- lelism than ILP, that is, the program units that are being simultaneously executed— threads—are larger or coarser than the finer-grained units—individual instructions. Hardware multithreading provides a means for systems to continue doing use- ful work when the task being currently executed has stalled—for example, if the current task has to wait for data to be loaded from memory. Instead of looking for parallelism in the currently executing thread, it may make sense to simply run an- other thread. Of course, for this to be useful, the system must support very rapid switching between threads. For example, in some older systems, threads were sim- ply implemented as processes, and in the time it took to switch between processes, thousands of instructions could be executed. In fine-grained multithreading, the processor switches between threads after each instruction, skipping threads that are stalled. While this approach has the potential to avoid wasted machine time due to stalls, it has the drawback that a thread that’s ready to execute a long sequence of instructions may have to wait to execute every instruction. Coarse-grained multithreading attempts to avoid this problem by only switching threads that are stalled waiting for a time-consuming operation to complete (e.g., a load from main memory). This has the virtue that switching threads doesn’t need to be nearly instantaneous. However, the processor can be idled on shorter stalls, and thread switching will also cause delays.
Simultaneous multithreading, or SMT, is a variation on fine-grained multi- threading. It attempts to exploit superscalar processors by allowing multiple threads to make use of the multiple functional units. If we designate “preferred” threads— threads that have many instructions ready to execute—we can somewhat reduce the problem of thread slowdown.
Computadoras paralelas (clusters)
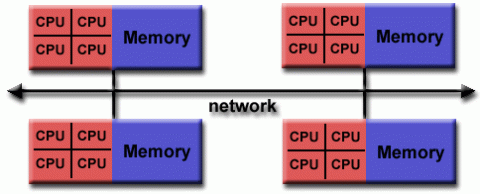
Las computadoras paralelas no son más que un conjunto de Memorias y CPUs conectadas en una red de forma inteligente. Basado en como es el acceso a la memoria de las unidades de procesamiento podemos clasificar a las computadores (clusters) en:
- Memoria distribuida (shared memory).
- Memoria compartida (distributed memory).
Shared Memory
En teoría estas arquitecturas permiten que los procesadores accedan a cualquier porción de la memoria libremente. Aunque los procesadores operen independientemente todos comparten los mismos recursos de memoria. Dentro de las arquitecturas de memoria compartida existen dos tipos básicos:
- Uniform Memory Access (UMA) Los procesadores son idénticos, y todos tienen igual acceso y en el mismo tiempo a la memoria. Representados por computadoras con symetric multi-processor (SMP).
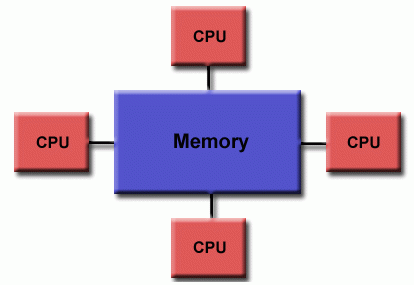
- Non-Uniform Memory Access (NUMA) Comumente formados por varios UMA interconectados. El acceso a memoria no es equitativo entre procesadores, aunque todos tengan acceso.
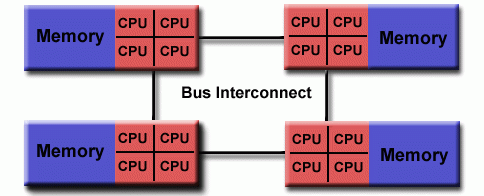
Ventajas:
- Tener un global address-space hace más facil la programación.
- Compartir datos entre tasks es rapido y uniforme debido a la proximidad a las CPUs.
Desventajas:
- Falta de escalabilidad entre memoria y CPUs. Más CPUs puede incrementa el tráfico.
- El programador tiene se tiene que ocupar de la sincronización que aseguren un correcto acceso a la memoria global.
Distributed Memory
En estas los procesadores tienen su propia memoria local. En ellas no existe el concepto de global address space a lo largo de todos los procesadores. Como cada procesador tiene su propia memoria local, opera de forma independiente. Por lo tanto tampoco aplica el concepto de cache cherency.
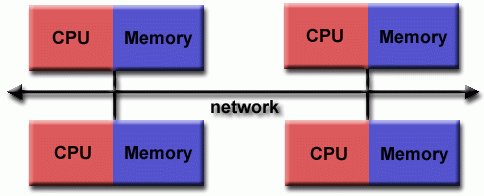
Ventajas:
- Escalabilidad de la memoria: más procesadores más memoria.
- Cada procesador accede rapidamente a su memoria sin interferencia del resto.
- Menos costosas y modulares.
Desventajas:
- El programador se tiene que ocupar de la comunicación entre procesadores.
- Puede ser dificil mapear estructras de datos basadas en memoria global a este tipo de organización de memoria.
- Acceso no uniforme a memoria. ya que la memoria de otros nodos tarda más que la local.
Hibridas
Las grandes supercomputadoras del mundo hoy en día adoptan una arquitectura míxta.
- La componente de memoria compartida puede ser una CPU multicore y/o una GPU ó acelerador.
- La componenente de memoria distribuida es una red (network) con multiples maquinas de memoria compartida que solo conocen su propia memoria, por lo que es necesario comunicación en red para mover datos de una maquina a otra.
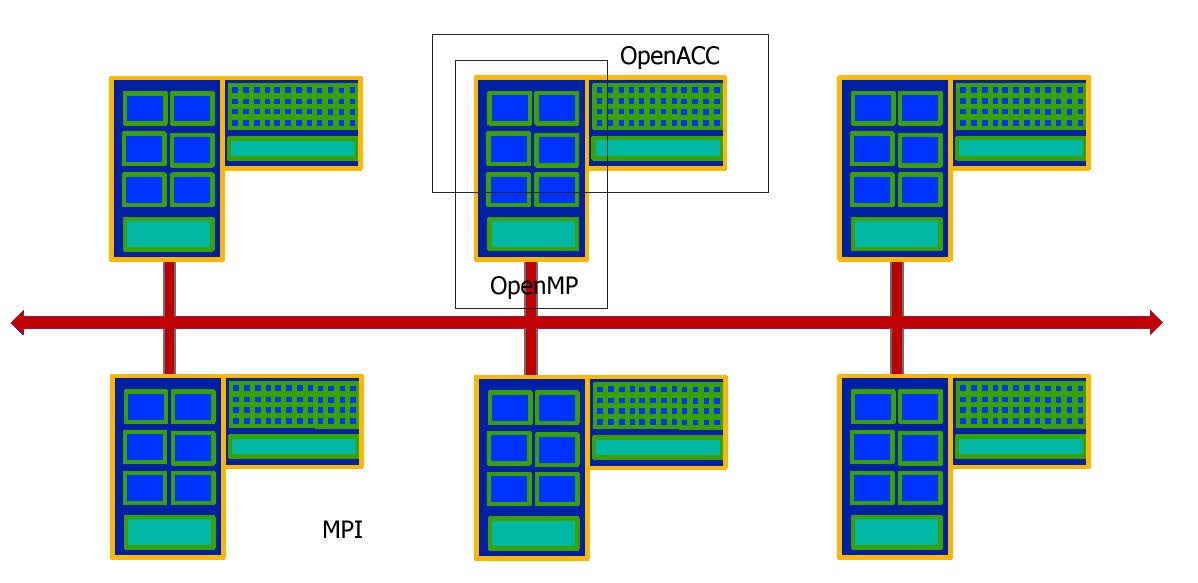
Tipos de paralelismo y taxonomía de Flynn
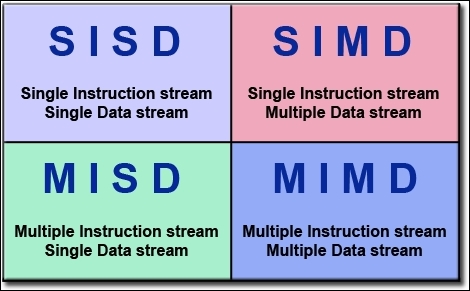
Flynn clasificó las computadoras en base a dos características: el paralelismo de procesos y paralelismo de datos.
- SISD (Single Instruction, Single Data) Es básicamente una computadora serial. Sólo se ejecuta una instrucción a la vez, y por lo tanto sólo una ruta de acceso a los datos es necesaria.
- SIMD (Single Instruction, Multiple Data) Todos los procesos ejecutan la misma instrucción en cada ciclo temporal. Y cada unidad de procesamiento puede operar en distintos datos. Sirven para problemas caracterizados por alto grado de regularidad (por ejemplo en procesamiento de imagenes y computación gráfica).
- MISD (Multiple Instruction, Single Data) Cada unidad de procesamiento actua de forma independiente por distintas vías de instrucciones. Pero hay un solo canal de datos que alimenta a las unidades de procesamiento. (Esta arquitectura no es muy común).
- MIMD (Multiple Instruction, Multiple Data) Cada procesador puede trabajar en una vía de instrucciones distinta, y el acceso a los datos puede ser diferente para cada uno. Es el tipo más común de computadoras paralelas.
Modelos de programación paralela
Los modelos de programación paralela son abstracciones por encima del hardware, y por lo tanto es importante resaltar que si bien algunos modelos se usan principalmente en determinadas arquitecturas, cualquiera de ellos puede ser usada en teoría en cualquier computadora independientemente de su arqutectura.
Existen varios modelos de programación paralela en uso:
- Shared memory (sin threads)
- Es el modelo más sencillo.
- Todos los tasks comparten un mismo address space donde pueden leer y escribir asincronicamente.
- Varios mecanismos como locks y semaforos son utilizados para controlar el acceso a la memoria compartida.
- Ejemplos: SHMEM
- Threads
- Es un tipo de programación de memoria compartida.
- Un proceso principal (usualmente conocido como master thread) tiene multiples procesos secundarios (slave threads)
- El master thread es la rama principal del proceso completo (por momentos se puede ejecutar serial).
- Ejemplos: openMP, POSIX
- Message Passing (de memoria distribuida)
- Un conjunto de tasks usan su porpia memoria local y varios de ellos pueden ó no residir en la misma maquina.
- El intercambio de datos entre tasks se realiza vía envio y recepción de mensajes.
- La transferencia de datos requiere operaciones coperativas que son realizadas por cada proceso.
- Ejemplos: MPI
- Paralelización de datos
- También conocido como PGAS (Partitioned Global Address space)
- El address space es tratado globalmente.
- La mayoria del trabajo paralelo se focaliza en realizar operaciones en un conjunto de datos.
- Los datos generalmente se organizan en una estructura común como arrays o cubos.
- Ejemplos: Coarray (Fortran)
- SPMD
- MPMD
Diseño de programas paralelos
Ian Foster’s methodology:
- Partitioning. Divide the computation to be performed and the data operated on by the computation into small tasks. The focus here should be on identifying tasks that can be executed in parallel.
- Communication. Determine what communication needs to be carried out among the tasks identified in the previous step.
- Agglomeration or aggregation. Combine tasks and communications identified in the first step into larger tasks. For example, if task A must be executed before task B can be executed, it may make sense to aggregate them into a single composite task.
- Mapping. Assign the composite tasks identified in the previous step to processes/threads. This should be done so that communication is minimized, and each process/thread gets roughly the same amount of work.
Definiciones y conceptos:
- Core/CPU/Procesador Son las unidades básicas de procesamiento que ejecutan una sola tarea. Las CPUs pueden estar organzadas en uno ó más sockets, cada socket con su propia memoria. Cuando una CPU tiene más de 2 sockets suele haber algun hardware que permita intercambiar memoria entre sockets.
- Nodo, básicamente una computadora. Generalmente está compuesto de varias CPUs, y tiene memoria propia.
- Cluster, conjunto de nodos interconectados entre sí en red formando una supercomputadora.
- Task (tarea), Sección lógica discreta de un trabajo computacional. Es tipicamente un subprograma que es ejecutado por un precesador. Un programa paralelo consiste en multiples tasks corriendo en multiples procesadores.
- Pipelining descomponer un task en pasos realizados por distintas CPUS como en una linea de montaje. es un tipo de computación paralela.
- Shared Memory arquitectura donde los procesadores tienen acceso directo a una memoria física común.
- Symmetric Multi-Processor (SMP) arquitectura donde los procesadores commparten el mismo address-space y tienen igual acceso a todos los recursos, memoria, discos, etc.
- Distributed Memory es una arquitectura donde cada procesador tiene su propia memoria física, y el acceso a la memoria entre CPUs se da a traves de una red.
- Comunicación los tasks en paralelo necesitan intercambiar datos, a este intercambio le llamamos comunicación.
- Syncronización es la coordinación de tasks paralelos en tempo real, suele involucrar esperar a que terminen otros procesos, lo que hace que el tiempo de ejecución incremente.
- Granularidad relación entre tiempo de computación y comunicación.
- Fina: Poco trabajo computacional destinado a comunicación de eventos.
- Gruesa: Alto tiempo destinado a comunicar nodos.
- sppedup relación entre tiempo de ejecucción de la versión serial y paralela de un mismo programa.
- Overhead, El tiempo requrido en coordinar tasks en lugar de estar haciendo trabajo útil. La coordinación puede incluir: iniciar tasks, sincronización, comunicación, uso de librerías especificas para paralelizar, y terminación.
- Paralelismos masivo arquitecturas con miles ó millones de unidades de procesamiento.
- Escalabilidad, Habilidad de mostrar un incremento proporcional en la velocidad con el incremento de recursos computacionales.
- FLOPs: de “Floating Point operation per second” (e.g suma, resta, multiplicacion, division) es una medida de performance.
Licensed MIT.